Do you want to buy antibiotics online without prescription? https://buyantibiotics24h.net/ - This is pharmacy online for you!
Microsoft word - data_access.doc
Data Access Patterns: Database Interactions in Object-Oriented Applications By Clifton Nock
Publisher Addison Wesley Pub Date September 15, 2003 ISBN
Decoupling Patterns
The previous chapter introduced the differences between application and middleware code.
Developing application code requires extensive domain knowledge and experience with the
business objects and processes that the software is supposed to model. On the other hand,
middleware code consists of more technical details, for which programmers who are used to
working with system-level resources and libraries are more qualified. Even small application
development groups can benefit by dividing software into layers that separate application and
middleware code. With a clean separation, application code deals exclusively with business
objects and logic while middleware code handles system and database details.
Defining the exact nature of this separation requires you to consider the types of maintenance and
enhancements that you expect to address in future releases. Ask these questions as you evaluate a
What features were dropped to meet schedules?— Even if you do not have time to
implement these features, you should consider building isolated placeholders that
What additional features do you expect your customers to request?— This is hard to
predict and requires research and imagination. Consider meeting with potential customers
for brainstorming sessions or usability testing. They can decide how to use your
application in their environment and can help you determine what features are important.
Do you expect the underlying data model to change?— Will you be modifying the data
model in future releases? Do you need to adapt to variations in the data model for
Do you expect to support new database platforms?— As you expand your customer base,
you may be forced to support additional database platforms that partnerships and
Do you plan to take advantage of advances in database technology?— If it is important
for your application to utilize cutting-edge database technology, then consider which
components need to adapt when something new comes along.
Are you dependent on third-party components?— When you find defects in your code,
you have complete control of the debugging and repair process. However, if you identify
a defect in a third-party component on which you depend, you have to wait for a fix from
its vendor. In addition, it is not uncommon for professional partnerships to dissolve. In
these cases, you may find yourself incorporating some competing technology in place of
Do you expect performance problems to occur?— Many best practices recommend
designing your software with a focus on structure and maintainability first, and fixing
performance problems later. Even when you follow this good advice, you can still predict
Decoupling patterns describe strategies for accommodating the issues that you raise when you
answer these questions. The primary, common goal of these patterns is to decouple orthogonal
software components. The extent to which you decouple components depends on how much you
expect them to vary independently. For instance, if you expect to support additional database
platforms in future releases, then it is a good idea to isolate all the code that is specific to a
particular database in a separate, swappable component.
Another common example of decoupling is defining the line between applications and
middleware. If you plan to expand your application or build new, similar applications, it is
beneficial to decouple them from middleware code. This allows you to reuse the same middleware
components and develop new applications more quickly.
The Data Model and Data Access
An application's data model is the static structure of its data. It encompasses one or more tables,
any associated indices, views, and triggers, plus any referential integrity features defined between
tables. The term "data model" also refers to an application's understanding of this static structure,
whether it is hardwired or discovered dynamically using metadata.
In most cases, you define a data model with data that is intended to be used exclusively by your
applications. From your customer's perspective, you encapsulate the specifics of the data model
within your applications. This grants you leeway to change or add to the data model, since you can
change the applications at the same time.
In some cases, you may publish your data model so that customers or consultants can integrate
your applications' data into those from other vendors. A common example of this is a generic
reporting tool that analyzes arbitrary data models and graphically summarizes their data. Another
scenario is when a customer integrates your applications with others using an enterprise
application integration (EAI) framework. If you support or encourage these scenarios, you are
more limited to the types of changes that you can make to your applications' data models. For
instance, you can add columns to a table, but you cannot remove columns without the risk of
A final scenario is when your customers define their own data models. You can design your
application to work explicitly with their legacy data. This degree of agility can be a significant
selling feature, but your application must readily adapt to a variety of table configurations.
In contrast to its data model, an application's data access refers to its dynamic mechanism for
reading and writing data. Data access code involves implementing direct database operations
You can choose to combine the notions of the data model and data access in your application.
Combining them results in one or more cohesive database components that can take advantage of
their data model knowledge to optimize data access operations. For example, this can allow a
database component to form queries that explicitly take advantage of known table indices, an
optimization that substantially improves query performance. On the other hand, separating an
application's data model and data access enables you to change or more readily adapt to changes
Domain Objects and Relational Data
A primary benefit of object-oriented programming is the ability to model your application domain
directly in software. Writing application code that manipulates Customer and Account objects is
more straightforward and less error-prone than computing offsets, passing large structures, and
True domain objects model application concepts, not necessarily those imposed by the data model.
This means that you should not always define objects based on the layout of tables and columns.
Doing so binds your domain objects to the data model and forces applications to understand these
details. Suppose you have CUSTOMERS and EMPLOYEES tables that, for historical reasons,
include similar but not identical address columns. The column names and types may be
inconsistent in the data model, but you can define Customer and Employee domain objects that
expose the same Address object type. This consistency can lead to common address processing
code that handles both customer and employee addresses identically.
Well-defined domain objects lead to cleaner application code, but present a problem for
middleware. Object-oriented programming and relational databases are significantly different
paradigms. Any software that utilizes both of these concepts must translate between them at some
point. Mapping relational data to domain objects requires you to process query results and create
analogous objects based on the application's data. Conversely, the other direction requires you to
generate database operations that make changes to persistent relational data that corresponds to
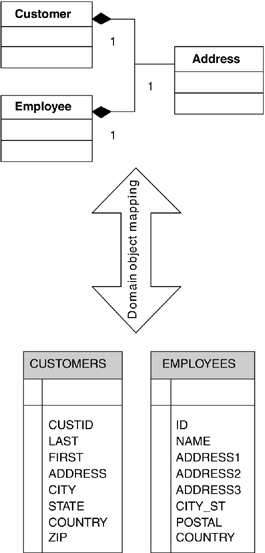
domain object changes. Figure P1.1 illustrates a mapping that translates between Customer,
Employee, and Address domain objects and the corresponding relational data:
Figure P1.1. A domain object mapping translates between domain objects and relational data.
Object-oriented databases that serialize and store objects directly in their run-time form provide
one solution. They eliminate the need for extra domain object mapping altogether. However,
object-oriented databases are not commonly used in enterprise software because they make it
harder to integrate with other products that depend heavily on relational data models. In addition,
most major database vendors do not provide object-oriented database engines.
Many applications therefore provide their own domain object mapping, intentionally or not. Even
the most basic applications tend to tackle this problem on their own. In its simplest form, solving
this problem requires an application to issue explicit database operations and manipulate
corresponding domain objects with brute force.
This strategy gets unwieldy when many tables and objects are involved. As the magnitude of the
mapping problems increases, you can address the problems with increasingly robust designs. One
solution is to define a set of common operations or a framework that populates and persists
domain objects in a uniform, consistent manner. Part 3, "Input/Output Patterns," describes some
patterns that can help you build these types of structures.
You can also consider building or buying a full-fledged object/relational mapping tool.
Object/relational mapping formalizes the process of mapping domain objects to and from
relational data. Object/Relational Map (53) describes this strategy in detail.
Decoupling Patterns
Decoupling patterns define how application code relates to its data model and data access code. As
you decide on an application architecture, you need to consider how much cohesion you want
between orthogonal components based on how much you expect them to vary independently.
Decoupling components also makes it easier to build and maintain them concurrently.
Another essential aspect of applying a decoupling pattern is defining the data access abstraction
that it exposes to the rest of the system. This abstraction must be sufficiently versatile to expose
the appropriate level of data access capabilities. On the other hand, it must also be broad enough
to make it feasible to plug in alternate data sources and algorithms if required.
This part of the book contains chapters for each of the following patterns:
Data Accessor (9)— Encapsulates physical data access details in a single component,
exposing only logical operations. Application code maintains knowledge about the
underlying data model, but is decoupled from data access responsibilities.
Active Domain Object (33)— Encapsulates the data model and data access details within
relevant domain object implementations. Active domain objects relieve application code
Object/Relational Map (53)— Encapsulate the mapping between domain objects and
relational data in a single component. An object/relational map decouples both
application code and domain objects from the underlying data model and data access
Layers (75)— Stack orthogonal application features that address data access issues with
These patterns differ in the level of database abstraction they expose to application code as well as
the organization of data model awareness and data access within the architecture. These
differences do not make them mutually exclusive. Layers (75) describes some examples of how
you might combine these patterns to build a solution that completely separates an application's
data model, data access, and domain object mapping. Extensive decoupling allows you to vary
each of these components independently and leads to agile and adaptable software designs.
Data Accessor Description
Encapsulates physical data access details in a single component, exposing only logical operations.
Application code maintains knowledge about the underlying data model, but is decoupled from
Developing enterprise software requires a rich mix of programming and business experience.
Application logic must accurately reflect business processes within its domain as well as utilize
data access and system resources efficiently.
Take an employee payroll system as an example. Consider a simple batch process that issues
reimbursement checks for employee expenses. This process requires the following database
1. Get a list of all employees for whom expense reimbursements are due.
2. For each employee in this list, get a list of active expenses reported.
3. Issue the employee a check for the total.
5. Delete the employee's active expense records.
The application logic for this process is straightforward. It does not stray much from the steps
listed here. However, its code has the potential to be the opposite. The database code for each of
these steps requires multiple physical database operations and management of the corresponding
resources. If you mix this code within the application logic, it quickly becomes convoluted.
The following code block illustrates this phenomenon. It implements the employee expense
reimbursement process using Java, JDBC, and SQL. Notice the mix of database, technology, and
= DriverManager.getConnection(.); // Get a list of employees that need to be // reimbursed for expenses. PreparedStatement employeesStatement = connection.prepareStatement( "SELECT EMPLOYEE_ID FROM P_EMPLOYEES " + "WHERE EXPENSE_FLAG = ?"); employeesStatement.setString(1, "Reimburse"); ResultSet employeesResultSet = employeesStatement.executeQuery(); while(employeesResultSet.next()) { int employeeID = employeesResultSet.getInt(1); // Get a list of expense records for the employee. PreparedStatement expensesStatement = connection.prepareStatement( "SELECT AMOUNT FROM A_EXPENSES " + "WHERE EMPLOYEE_ID = ?"); expensesStatement.setInt(1, employeeID); ResultSet expensesResultSet = expensesStatement.executeQuery(); // Total the expense records. long totalExpense = 0; while(expensesResultSet.next()) { long amount = expensesResultSet.getLong(1); totalExpense += amount; } // Issue the employee a check for the sum. issueEmployeeCheck(employeeID, totalExpense); // Update the employee's expense status to none. PreparedStatement updateExpenseStatus = connection.prepareStatement( "UPDATE P_EMPLOYEES SET EXPENSE_FLAG = ? " + "WHERE EMPLOYEE_ID = ?"); updateExpenseStatus.setString(1, "None"); updateExpenseStatus.setInt(2, employeeID); updateExpenseStatus.executeUpdate(); updateExpenseStatus.close(); // Delete all of the employee's expense records. PreparedStatement deleteExpenseRecords = connection.prepareStatement( "DELETE FROM A_EXPENSES WHERE EMPLOYEE_ID = ?"); deleteExpenseRecords.setInt(1, employeeID); deleteExpenseRecords.executeUpdate(); deleteExpenseRecords.close();
expensesStatement.close(); expensesResultSet.close(); } employeesResultSet.close(); employeesStatement.close();
Now, scale this implementation style to an entire suite of applications. Having database access
code sprinkled throughout application logic makes it especially hard to maintain. One reason is
that developers who support and enhance this code must be intimately familiar with both the
application logic and data access details. Bigger problems arise when you need to support
additional database platforms or incorporate optimizations such as a connection pool. With data
access code spread throughout an entire product, these enhancements become major engineering
projects that span a majority of the product's source files.
The Data Accessor pattern addresses this problem. Its primary objective is to build an abstraction
that hides low-level data access details from the rest of the application code. This abstraction
exposes only high-level, logical operations. With a robust abstraction in place, application code
focuses on operations from the domain point of view. This focus results in clean, maintainable
application logic. Figure 1.1 illustrates how the data accessor abstraction and implementation
decouple the application logic from the physical database driver:
Figure 1.1. The Data Accessor pattern decouples application logic from the physical data access implementation by defining an abstraction that exposes only logical operations to the application code.
The data accessor implementation handles all the physical data access details on behalf of the
application code. This isolation makes it possible to fix database access defects and incorporate
new features in a single component and affect the entire system's operation.
The logical operations that you expose depend on your application's data access requirements. In
the employee expense process described earlier, it might be helpful to define logical read and
write operations in terms of table and column names without requiring the application code to
issue SQL statements or directly manage prepared statements or result sets. The "Sample Code"
section in this chapter contains an example of some simple logical database operations.
You can also use a data accessor to hide a database's semantic details as well as constraints that
your system's architecture imposes. Here are some ideas for encapsulating physical data access
Expose logical operations; encapsulate physical operations— The data accessor
abstraction can expose logical database operations such as read, insert, update, and delete,
instead of requiring application code to issue SQL statements or something at a similar,
lower level. The data accessor implementation generates efficient SQL statements on the
application's behalf. This is beneficial because it saves application developers from
learning the intricacies of SQL and also allows you to change your strategies for issuing
these operations without affecting application code.
Expose logical resources; encapsulate physical resources— The more details you hide
from application code, the more you are at liberty to change. One example of this is
database resource management. If you let applications manage their own database
connections, it is hard to incorporate enhancements like connection pooling, statement
You may find it convenient to provide logical connection handles to applications.
Applications can use these handles to associate operations with physical connection pools
and physical connection mapping strategies. The data accessor implementation is
responsible for resolving exact table locations and physical connections at runtime. This
is especially convenient when data is distributed across multiple databases.
Normalize and format data— The physical format of data is not necessarily the most
convenient form for applications to work with, especially if the format varies across
multiple database platforms. For example, databases often store and return binary large
object (BLOB) data as an array or stream of raw bytes. The data accessor implementation
can be responsible for deserializing these bytes and handing an object representation to
Encapsulate platform details— Business relationships change frequently. If your
company initiates a new partnership that requires your application to support additional
database products, encapsulating any database platform details within a data accessor
implementation facilitates the enhancements. If you take this as far as to hide any
particular technology, such as SQL, then you can more readily support non-SQL
databases as well, all without extensive application code changes.
Encapsulate optimization details— Application behavior should not directly depend on
optimizations like pools and caches because that hinders your ability to change these
optimizations in the future. If you only allow application code to allocate logical
resources and issue logical operations, then you retain the freedom to implement these
logical operations within the data accessor implementation with whatever optimized
The Data Accessor pattern makes application code more amenable to enhancement and
optimization. In addition, it defines a clear separation between application domain code and data
access details. Besides the maintenance issues described throughout this chapter, this separation
benefits engineering teams as well, since you can divide the development of different components
among multiple programmers with diverse skills and experience.
Applicability
You want to hide physical data access complexity and platform issues from application
logic. Doing so keeps application logic cleaner and more focused on the business objects
You want to manage additional semantics over and above those that the underlying
physical database driver provides. Database drivers do not normally handle data
distribution or application-level locking mechanisms because the implementation of these
features depends heavily on an application's topological and semantic architecture.
You want to define multiple data access implementations and choose between them at
runtime. Different implementations might accommodate multiple database platforms or
even completely new database technology, such as extensible markup language (XML)
Structure
Figure 1.2 illustrates the static structure of the Data Accessor pattern. The DataAccessor interface
defines the data access abstraction in terms of logical operations that the application code uses.
You must define these operations to be extensive enough so that applications can do useful work
without forcing applications to use unnatural constructs or workarounds. You can tailor the exact
logical operation semantics to keep application code as straightforward as possible. You must also
be careful not to expose any physical semantics in these logical operations. Doing so enables
application code to depend on exposed physical features, making it difficult to change later. Also
be mindful that you do not need to define the entire set of logical operations in a single interface
as Figure 1.2 shows. It is common to separate logical query, update, result set, and transaction
Figure 1.2. The static structure of the Data Accessor pattern.
ConcreteDataAccessor provides the implementation of logical operations in terms of physical
database operations. This class depends directly on specific database technology. You may define
more than one concrete implementation if you need to support different physical database
Notice that this pattern encapsulates an application's data access, but it does not encapsulate its
Interactions
Figure 1.3 portrays what happens when an application invokes operationA on a
ConcreteDataAccessor. The ConcreteDataAccessor implements the logical operation in terms of
one or more physical operations. It is also likely to interpret or convert the input and output data as
well as handle physical resource management on the application's behalf.
Figure 1.3. An application invokes operationA on a ConcreteDataAccessor. Consequences
The Data Accessor pattern has the following consequences:
Benefits Clean application code— Application code that is replete with data access details is
difficult to read and maintain. Application logic tends to become obscured by the many
calls necessary to do even simple database calls. When an application uses a well-
designed data accessor abstraction that exposes logical database operations, its code can
Adoption of new database features or platforms— When physical data access code is
spread throughout a system, it is hard to add support for new features or platforms
because it involves searching the entire code base and replacing or adding new calls
where necessary. This process is tedious and error-prone. When a data accessor
implementation encapsulates physical data access code, you only have one isolated
Incorporation of optimization strategies— Data access code usually is a primary analysis
focal point when tuning an application's performance. Data access code is a common
bottleneck source and simple optimizations often have significant effects. When data
access code is spread across a system, it requires much more effort to apply and measure
optimizations because you must repeat their implementations multiple times. When you
encapsulate all physical data access code within a data accessor implementation, you can
incorporate an optimization strategy once and it immediately applies across the entire
Swappable physical data access implementations— You can swap among multiple data
accessor implementations without changing application code. This enables you to
conveniently support multiple, diverse database platforms and technologies.
Drawback Limits application control of data access— Application code is limited to the logical
operations defined by a data accessor abstraction. When a data accessor abstraction is not
well-designed or versatile enough for an application's data access requirements, the
application code may resort to unnatural or awkward workarounds that ultimately lead to
Strategies
Consider these strategies when designing a data accessor abstraction:
Define versatile logical operations— Keep in mind that while a data accessor abstraction
hides many data access details from application code, the logical operations that it defines
must not unnecessarily limit it. A truly useful data accessor abstraction exposes simple,
common database operations, but also allows versatility. If the abstraction does not
provide all the logical database operations that applications require, then applications
need to use the operations that it does define in unexpected or inefficient combinations.
This can lead to more convoluted code than if it handles data access directly.
For example, the data accessor abstraction defined in the "Sample Code" section allows
the client to designate a selection row when it issues a read operation. A selection row is
roughly analogous to a partial or full primary key value. This feature works fine for the
sample client application, but suppose another application needed to read a range of
employee identifiers. The abstraction does not expose any support for this type of query,
so the application would need to read all records and explicitly filter them. In this case,
the data accessor abstraction's semantics have caused the application code to be less
One strategy for avoiding this scenario is to research application use cases before
designing a data accessor abstraction. Writing prototype or hypothetical application code
helps you understand what features application developers need and what semantics keep
On the other hand, be wary of designing data accessor abstractions too heavily. Adding
operations for speculated scenarios may impose a significant development burden and
unnecessary complexity on data accessor implementations.
Incorporate enhancement and optimization points— A common development tradeoff is
to remove features to meet schedule. While architects and developers can plan full-
featured, highly scalable applications, they may not be successful if they take years to
develop. The Data Accessor pattern enables you to design applications so that you can
readily incorporate additional database features and optimizations in subsequent product
releases. Even if you do not have enough development resources to incorporate all of an
application's desired data access features, you should consider them and determine where
A common example involves database platform support. In the first product release, you
can deliver a data accessor implementation that supports a single database product using
SQL access. If you hide all platform and SQL details within the data accessor
implementation, you can add other platforms and database support in later releases
without requiring changes to application code.
You can also approach optimizations such as connection pools with a similar strategy.
Hiding connection management within a data accessor implementation enables you to
conveniently integrate optimizations like these in a single component, again affecting the
entire system's performance characteristics without requiring any application code to
Guard against inefficient application usage— It is common for application code to
employ physical database access code inefficiently. This can have significant negative
effects on overall system performance. One example is an application that prepares the
same statement multiple times. This application's data access code is likely to be
measurably slower than the code of an application that reuses statement handles where
possible. However, recycling statement handles adds complexity to application code,
making them good candidates for encapsulation within a data accessor implementation.
Design your data accessor abstraction so that it is impossible or improbable that
application usage will have a significant effect on performance or storage overhead. For
example, if you expose the notion of a database connection, make it a logical connection
that does not directly incur physical database connection overhead. This way, if an
application opens and closes logical connections repeatedly, it will not affect overall
The data accessor abstraction offers a point where you can bridge the gap between a
robust, application-friendly interface and a highly optimized, full-featured
To completely insulate applications from changes to a particular data accessor implementation,
you should minimize all direct references to it. Instead, write application code exclusively in terms
However, you need to instantiate data accessor implementation objects at some point. These are
three alternatives for centralizing this instantiation so that it is easier to alter in the future:
Singleton data accessor implementation— Define a global, singleton instance of a data
accessor implementation that any application code can access. The singleton instance
initializes itself only once and isolates its initialization details.
Initialization and parameter passing— You can instantiate a single data accessor
implementation object in your application's initialization code and pass it to any other
application code that needs it. This strategy isolates initialization code to a single
component, but it requires that many of the application classes' constructors and
Data accessor factory— You can define a globally accessible factory class to instantiate
new data accessor implementation instances. You still encapsulate the data accessor
initialization within a single module, the factory returns new data accessor
implementation instances whenever an application requests them.
Sample Code
This code example illustrates a data accessor abstraction that defines logical database access
operations for reading, inserting, updating, and deleting data. Notice that this interface's callers do
not need to manage database resources, issue SQL statements, or make direct JDBC calls. The
logical operations define the data they are accessing, but do not disclose any underlying
Reads data from a table. @param table The table. @param columns The columns to read, or null to read all the columns in the table. @param selectionRow A set of filter columns and values used to subset the rows, or null to read all the rows in the table. @param sortColumns The columns to sort, or null to read without sorting. @return The list of rows. **/ List read(String table, String[] columns, Row selectionRow, String[] sortColumns) throws DataException; /** Inserts data into a table. @param table The table. @param rows The rows to insert. **/ void insert(String table, List rows) throws DataException; /** Updates data in a table. @param table The table. @param selectionRow A set of filter columns and values used to subset the rows, or null to update all of the rows in the table. @param updateRow A set of update columns and values. **/ void update(String table, Row selectionRow, Row updateRow) throws DataException; /** Deletes data from a table. @param table The table. @param selectionRow A set of filter columns and values used to subset the rows, or null to delete all of the rows in the table. **/ void delete(String table, Row selectionRow) throws DataException; }
ConcreteDataAccessor is a DataAccessor implementation that operates in terms of multiple JDBC
connections. This class is responsible for:
Managing database resources such as connections, statement handles, and result sets.
Resolving qualified table names and physical database connections. For the sake of this
example, suppose that this application accesses accounting and payroll data on different
systems. ConcreteDataAccessor maps logical operations to databases based on the format
of the table name provided by the client. This rule is an arbitrary constraint that is part of
this particular application's design. However, you can implement more robust, directory-
based distribution mechanisms the same way.
As you read through this example, consider some other data access details that you could
implement within a concrete data accessor implementation, such as customized data conversion,
user-based authorization, and logical operation logging.
public class ConcreteDataAccessor implements DataAccessor { private Connection accountingConnection; private Connection payrollConnection; private Connection otherConnection; /** Constructs a ConcreteDataAccessor object. */ public ConcreteDataAccessor() throws DataException { try { accountingConnection = DriverManager.getConnection(.); payrollConnection = DriverManager.getConnection(.); otherConnection = DriverManager.getConnection(.); } catch(SQLException e) { throw new DataException( "Unable to construct DataAccessor", e); } } /** Reads data from a table. @param table The table. @param columns The columns to read, or null to read all the columns in the table. @param selectionRow A set of filter columns and values used to subset the rows, or null to read all the rows in the table. @param sortColumns The columns to sort, or null to read without sorting.
@return The list of rows. **/ public List read(String table, String[] columns, Row selectionRow, String[] sortColumns) throws DataException { try { // Generate the SQL SELECT statement based on // the caller's input. StringBuffer buffer = new StringBuffer(); buffer.append("SELECT "); // List the columns if the caller specified any. if (columns != null) { for(int i = 0; i < columns.length; ++i) { if (i > 0) buffer.append(", "); buffer.append(columns[i]); } } else buffer.append(" * "); // Include the resolved qualified table name. buffer.append(" FROM "); buffer.append(resolveQualifiedTable(table)); // Generate the WHERE clause if the caller // specified a selection row. if (selectionRow != null) { buffer.append( generateWhereClause(selectionRow)); } // Generate the ORDER BY clause if the caller // specified sort columns. if (sortColumns != null) { buffer.append(" ORDER BY "); for(int i = 0; i < sortColumns.length; ++i) { if (i > 0) buffer.append(", "); buffer.append(sortColumns[i]); buffer.append(" ASC"); } } // Resolve the appropriate connection for this // table. Connection connection = resolveConnection(table); synchronized(connection) {
// Execute the query. Statement statement = connection.createStatement(); ResultSet resultSet = statement.executeQuery( buffer.toString()); ResultSetMetaData rsmd = resultSet.getMetaData(); int columnCount = rsmd.getColumnCount(); // Create a list of result rows based on the // contents of the result set. List resultRows = new LinkedList(); while(resultSet.next()) { Row resultRow = new Row(); for(int i = 1; i <= columnCount; ++i) { resultRow.addColumn( rsmd.getColumnName(i), resultSet.getObject(i)); } resultRows.add(resultRow); } // Release database resources and return. resultSet.close(); statement.close(); return resultRows; } } catch(SQLException e) { throw new DataException("Unable to read table " + table, e); } } /** Inserts data into a table. @param table The table. @param rows The rows to insert. **/ public void insert(String table, List rows) throws DataException { try { for(Iterator i = rows.iterator(); i.hasNext(); ) { Row row = (Row)i.next(); // Generate the SQL INSERT statement based on // the caller's input. StringBuffer buffer = new StringBuffer(); buffer.append("INSERT INTO ");
buffer.append(resolveQualifiedTable(table)); // List the column names. buffer.append(" ("); boolean firstColumn = true; for(Iterator j = row.columns(); j.hasNext();){ if (!firstColumn) buffer.append(", "); else firstColumn = false; buffer.append(j.next()); } // List the column values. buffer.append(") VALUES ("); firstColumn = true; for(Iterator j = row.columns(); j.hasNext();){ if (!firstColumn) buffer.append(", "); else firstColumn = false; String column = (String)j.next(); Object columnValue = row.getColumnValue(column); buffer.append( generateLiteralValue(columnValue)); } // Resolve the appropriate connection for // this table. Connection connection = resolveConnection(table); synchronized(connection) { // Execute the insert. Statement statement = connection.createStatement(); statement.executeUpdate( buffer.toString()); statement.close(); } } } catch(SQLException e) { throw new DataException( "Unable to insert into table " + table, e); } } /** Updates data in a table.
@param table The table. @param selectionRow A set of filter columns and values used to subset the rows, or null to update all the rows in the table. @param updateRow A set of update columns and values. **/ public void update(String table, Row selectionRow, Row updateRow) throws DataException { try { // Generate the SQL UPDATE statement based on the // caller's input. StringBuffer buffer = new StringBuffer(); buffer.append("UPDATE "); buffer.append(resolveQualifiedTable(table)); // Generate the SET clause. buffer.append(" SET "); boolean firstColumn = true; for(Iterator i=updateRow.columns(); i.hasNext();){ if (!firstColumn) buffer.append(", "); else firstColumn = false; String column = (String)i.next(); buffer.append(column); buffer.append(" = "); Object columnValue = updateRow.getColumnValue(column); buffer.append( generateLiteralValue(columnValue)); } // Generate the WHERE clause if the caller // specified a selection row. if (selectionRow != null) { buffer.append( generateWhereClause(selectionRow)); } // Resolve the appropriate connection for this // table. Connection connection = resolveConnection(table); synchronized(connection) { // Execute the update. Statement statement = connection.createStatement(); statement.executeUpdate( buffer.toString());
statement.close(); } } catch(SQLException e) { throw new DataException( "Unable to update table " + table, e); } } /** Deletes data from a table. @param table The table. @param selectionRow A set of filter columns and values used to subset the rows, or null to delete all the rows from the table. **/ public void delete(String table, Row selectionRow) throws DataException{ try { // Generate the SQL DELETE statement based on the // caller's input. StringBuffer buffer = new StringBuffer(); buffer.append("DELETE FROM "); buffer.append(resolveQualifiedTable(table)); // Generate the WHERE clause if the caller // specified a selection row. if (selectionRow != null) { buffer.append( generateWhereClause(selectionRow)); } // Resolve the appropriate connection for // this table. Connection connection = resolveConnection(table); synchronized(connection) { // Execute the delete. Statement statement = connection.createStatement(); statement.executeUpdate(buffer.toString()); statement.close(); } } catch(SQLException e) { throw new DataException( "Unable to delete from table " + table, e); } }
/** Resolves the connection based on the table name. */ private Connection resolveConnection(String table) { // These are just arbitrary rules for the sake // of this example. if (table.startsWith("A")) return accountingConnection; else if (table.startsWith("P")) return payrollConnection; else return otherConnection; } /** Resolves the qualified table name. */ private String resolveQualifiedTable(String table) { // These are just arbitrary rules for the sake // of this example. if (table.startsWith("A")) return "ACCTDATA." + table; else if (table.startsWith("P")) return "PAYROLL." + table; else return table; } /** Generates a SQL literal string. */ private String generateLiteralValue(Object literalValue) { StringBuffer buffer = new StringBuffer(); if (!(literalValue instanceof Number)) buffer.append("'"); buffer.append(literalValue); if (!(literalValue instanceof Number)) buffer.append("'"); return buffer.toString(); } /** Generates a SQL WHERE clause based on a selection row. */ private String generateWhereClause(Row selectionRow) { StringBuffer buffer = new StringBuffer(); buffer.append(" WHERE "); boolean firstColumn = true; for(Iterator i=selectionRow.columns(); i.hasNext();){ if (!firstColumn)
buffer.append(" AND "); else firstColumn = false; String column = (String)i.next(); buffer.append(column); buffer.append(" = "); Object columnValue = selectionRow.getColumnValue(column); buffer.append( generateLiteralValue(columnValue)); } return buffer.toString(); } }
Row is a simple helper class that DataAccessor uses to represent logical input and output data.
Keep in mind that if you had chosen to return a java.sql.ResultSet instead, you would have
immediately coupled your application directly to JDBC technology, preventing future, transparent
moves to non-JDBC databases in the future.
public class Row { private Map contents = new HashMap(); public Row() { } public Row(String column, Object columnValue) { contents.put(column, columnValue); } public void addColumn(String column, Object columnValue) { contents.put(column, columnValue); } public Object getColumnValue(String column) { return contents.get(column); } public Iterator columns() { return contents.keySet().iterator(); } }
DataException represents any exception that is thrown within the context of a data accessor
implementation. This exception class wraps concrete exceptions like java.sql.SQLExceptions.
This is another step toward decoupling consuming application code from the
ConcreteDataAccessor's underlying JDBC implementation.
extends Exception { DataException(String message, Throwable cause) { super(message, cause); } }
Next is an example of a client that uses a data accessor abstraction to implement the employee
expense reimbursement check process described in the "Context" section. Notice how there is no
JDBC or SQL code. Instead, the example does all its data access using the logical operations
provided by the data accessor abstraction.
// Get a list of employees that need to be // reimbursed for expenses. List employeeRows = dataAccessor.read("P_EMPLOYEES", null, new Row("EXPENSE_FLAG", "Reimburse"), null); for(Iterator i = employeeRows.iterator(); i.hasNext(); ) { Row employeeRow = (Row)i.next(); Integer employeeID = (Integer)employeeRow.getColumnValue("EMPLOYEE_ID"); Row employeeSelectionRow = new Row("EMPLOYEE_ID", employeeID); // Get a list of expense records for the employee. List expenseRows = dataAccessor.read("A_EXPENSES", new String[] { "AMOUNT" }, employeeSelectionRow, null); // Total the expense records. long totalExpense = 0; for(Iterator j = expenseRows.iterator(); j.hasNext(); ) { Row expenseRow = (Row)j.next(); long amount = ((Long)expenseRow.getColumnValue("AMOUNT")) .longValue(); totalExpense += amount; } // Issue the employee a check for the sum. issueEmployeeCheck(employeeID, totalExpense); // Update the employee's expense status to none.
dataAccessor.update("P_EMPLOYEES", employeeSelectionRow, new Row("EXPENSE_FLAG", "None")); // Delete all the employee's expense records. dataAccessor.delete("A_EXPENSES", employeeSelectionRow); }
Related Patterns and Technology
Data Accessor is also known as Data Access Object [Alur 2001] and Logical Connection.
A data accessor implementation is an instance of Adapter [Gamma 1995] since it adapts
an abstraction that is convenient for application usage to a particular physical database
Singleton [Gamma 1995] and Abstract Factory [Gamma 1995] describe strategies for
isolating a data accessor instantiation within a single component that is conveniently
[Marinescu 2002] and [Matena 2003] describe an alternate approach to encapsulating
physical data access operations called Data Access Command Beans. Data Access
Command Beans define logical database operations using Command [Gamma 1995]
Consider using Data Accessor to abstract the data access portion of an Active Domain
Object (33) or Object/Relational Map (53).
One or more data accessor abstractions can make up layers, as described in Layers (75).
You can also define multiple data accessor abstractions for different layers. Each
abstraction might address a different aspect or level of data access functionality.
Family Disaster Plan Is your family prepared for a weather emergency?SafeSide® is designed to raise awareness of the Name _____________________________________importance of disaster preparedness by providing School ____________________________________you with tools to protect and prepare yourself and Home Address _____________________________your family for severe weather events. C
SELECTION OF SUSCEPTIBILITY TEST BROTH Use Sensititre CAMHBT for rapid growing mycobacteria, Nocardia and other aerobic Actinomycetes or Mueller Hinton broth with OADC for slow growing mycobacteria. Sensititre broths are performance tested for use with SENSITITRE® Broth Microdilution (MIC) Method: INOCULATION AND INCUBATION For Rapidly Growing Mycobacteria (RGM), Slowly
 True domain objects model application concepts, not necessarily those imposed by the data model.
This means that you should not always define objects based on the layout of tables and columns.
Doing so binds your domain objects to the data model and forces applications to understand these
details. Suppose you have CUSTOMERS and EMPLOYEES tables that, for historical reasons,
include similar but not identical address columns. The column names and types may be
inconsistent in the data model, but you can define Customer and Employee domain objects that
expose the same Address object type. This consistency can lead to common address processing
code that handles both customer and employee addresses identically.
Well-defined domain objects lead to cleaner application code, but present a problem for
middleware. Object-oriented programming and relational databases are significantly different
paradigms. Any software that utilizes both of these concepts must translate between them at some
point. Mapping relational data to domain objects requires you to process query results and create
analogous objects based on the application's data. Conversely, the other direction requires you to
generate database operations that make changes to persistent relational data that corresponds to
domain object changes. Figure P1.1 illustrates a mapping that translates between Customer,
Employee, and Address domain objects and the corresponding relational data:
Figure P1.1. A domain object mapping translates between domain objects and
True domain objects model application concepts, not necessarily those imposed by the data model.
This means that you should not always define objects based on the layout of tables and columns.
Doing so binds your domain objects to the data model and forces applications to understand these
details. Suppose you have CUSTOMERS and EMPLOYEES tables that, for historical reasons,
include similar but not identical address columns. The column names and types may be
inconsistent in the data model, but you can define Customer and Employee domain objects that
expose the same Address object type. This consistency can lead to common address processing
code that handles both customer and employee addresses identically.
Well-defined domain objects lead to cleaner application code, but present a problem for
middleware. Object-oriented programming and relational databases are significantly different
paradigms. Any software that utilizes both of these concepts must translate between them at some
point. Mapping relational data to domain objects requires you to process query results and create
analogous objects based on the application's data. Conversely, the other direction requires you to
generate database operations that make changes to persistent relational data that corresponds to
domain object changes. Figure P1.1 illustrates a mapping that translates between Customer,
Employee, and Address domain objects and the corresponding relational data:
Figure P1.1. A domain object mapping translates between domain objects and 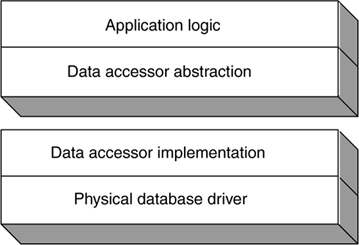 expensesStatement.close(); expensesResultSet.close(); } employeesResultSet.close(); employeesStatement.close();
Now, scale this implementation style to an entire suite of applications. Having database access
code sprinkled throughout application logic makes it especially hard to maintain. One reason is
that developers who support and enhance this code must be intimately familiar with both the
application logic and data access details. Bigger problems arise when you need to support
additional database platforms or incorporate optimizations such as a connection pool. With data
access code spread throughout an entire product, these enhancements become major engineering
projects that span a majority of the product's source files.
The Data Accessor pattern addresses this problem. Its primary objective is to build an abstraction
that hides low-level data access details from the rest of the application code. This abstraction
exposes only high-level, logical operations. With a robust abstraction in place, application code
focuses on operations from the domain point of view. This focus results in clean, maintainable
application logic. Figure 1.1 illustrates how the data accessor abstraction and implementation
decouple the application logic from the physical database driver:
Figure 1.1. The Data Accessor pattern decouples application logic from the
expensesStatement.close(); expensesResultSet.close(); } employeesResultSet.close(); employeesStatement.close();
Now, scale this implementation style to an entire suite of applications. Having database access
code sprinkled throughout application logic makes it especially hard to maintain. One reason is
that developers who support and enhance this code must be intimately familiar with both the
application logic and data access details. Bigger problems arise when you need to support
additional database platforms or incorporate optimizations such as a connection pool. With data
access code spread throughout an entire product, these enhancements become major engineering
projects that span a majority of the product's source files.
The Data Accessor pattern addresses this problem. Its primary objective is to build an abstraction
that hides low-level data access details from the rest of the application code. This abstraction
exposes only high-level, logical operations. With a robust abstraction in place, application code
focuses on operations from the domain point of view. This focus results in clean, maintainable
application logic. Figure 1.1 illustrates how the data accessor abstraction and implementation
decouple the application logic from the physical database driver:
Figure 1.1. The Data Accessor pattern decouples application logic from the 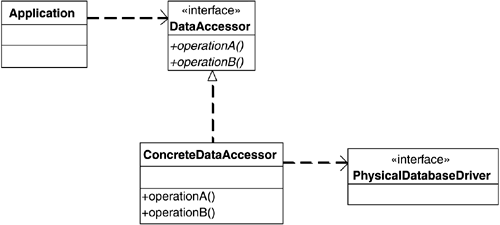 You want to hide physical data access complexity and platform issues from application
logic. Doing so keeps application logic cleaner and more focused on the business objects
You want to manage additional semantics over and above those that the underlying
physical database driver provides. Database drivers do not normally handle data
distribution or application-level locking mechanisms because the implementation of these
features depends heavily on an application's topological and semantic architecture.
You want to define multiple data access implementations and choose between them at
runtime. Different implementations might accommodate multiple database platforms or
even completely new database technology, such as extensible markup language (XML)
Structure
You want to hide physical data access complexity and platform issues from application
logic. Doing so keeps application logic cleaner and more focused on the business objects
You want to manage additional semantics over and above those that the underlying
physical database driver provides. Database drivers do not normally handle data
distribution or application-level locking mechanisms because the implementation of these
features depends heavily on an application's topological and semantic architecture.
You want to define multiple data access implementations and choose between them at
runtime. Different implementations might accommodate multiple database platforms or
even completely new database technology, such as extensible markup language (XML)
Structure 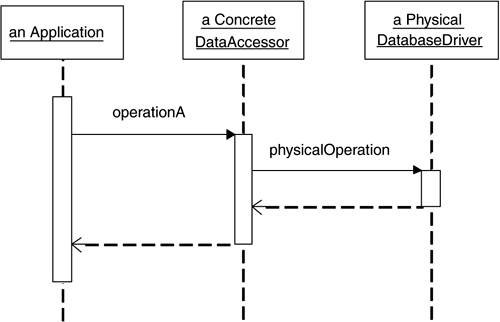 Figure 1.3 portrays what happens when an application invokes operationA on a
ConcreteDataAccessor. The ConcreteDataAccessor implements the logical operation in terms of
one or more physical operations. It is also likely to interpret or convert the input and output data as
well as handle physical resource management on the application's behalf.
Figure 1.3. An application invokes operationA on a ConcreteDataAccessor.
Figure 1.3 portrays what happens when an application invokes operationA on a
ConcreteDataAccessor. The ConcreteDataAccessor implements the logical operation in terms of
one or more physical operations. It is also likely to interpret or convert the input and output data as
well as handle physical resource management on the application's behalf.
Figure 1.3. An application invokes operationA on a ConcreteDataAccessor.