Do you want to buy antibiotics online without prescription? https://buyantibiotics24h.net/ - This is pharmacy online for you!
People.dsv.su.se
Abstract. We describe a method for modifying a monolingual Englishquestion answering system to allow it to accept French questions. Ourmethod relies on a statistical translation engine to translate keywords,and a set of manually written rules for analyzing French questions. Theadditional steps performed by the cross-language system lower its per-formance by 28% compared to the original system.
A question answering (QA) system can be described as a particular type of searchengine that allows a user to ask a question using natural language instead of anartificial query language. Moreover, a QA system pinpoints the exact answer inthe document, while a classical search engine returns entire documents that haveto be skimmed by the user.
Clarke [1] has shown that, for document collections smaller than 500 GB
(100 billion words), the bigger the size of the collection, the better the perfor-mance of their QA system. If we suppose that an English speaker has access toabout 10 times more digital documents — webpages, encyclopaedias on CDs,etc. — than a French speaker (estimation based on the number of pages on theweb, see Fig. 1), there is no doubt that a QA system designed for French speak-ers but able to search English documents would open new possibilities both interms of the quantity of topics covered and the quality of the answers.
We had previously developed the Quantum QA system [2] for the TREC eval-
uation campaigns. This system operates in English only: the question must beasked in English, the document collection is in English and the answer extrac-tion is performed in English. For the purpose of a pilot project conducted withthe National Research Council of Canada [3], we transformed Quantum into abilingual system to allow French speakers to ask their questions in French andto get answers in French as well, but using an English document collection. Weentered the cross-language QA track at CLEF 2003 with this bilingual systemwithout further modifications.
Fig. 1. Online language populations (March 2003), on a total of 640 million webpages. Source: http://www.glreach.com/globstats
Quantum was developped primarily for the TREC evaluation campaigns. It wasdesigned to answer simple, syntactically well-formed, short and factual Englishquestions such as the following from past campaigns: What is pilates? Whowas the architect of Central Park? How wide is the Atlantic Ocean? At whatspeed does the Earth revolve around the sun? Where is the French consulatein New York? The document collection from which the answers are extractedare news from major newswires. For more details on the track and the systemrequirements, see the description of the TREC-11 QA track [4].
The architecture of the Quantum monolingual system is shown on Fig. 2,
along with a sample question from the CLEF set. In the following sections, wedescribe only the elements that are relevant to the modifications we made inorder to make the system cross-lingual.
The goal of the question analysis phase is to determine the expected type of theanswer to a particular question, and thus to determine the answer extractionmechanism — or extraction function — to use. Some of the extraction functionsrequire an additional parameter called the question’s focus. The focus is a word
Fig. 2. Architecture of the monolingual version of Quantum. The question, the docu-ments and the answer are all in English (E).
or group of words that appears in the question and that is closely related tothe answer. For instance, the answer to With what radioactive substance wasEda Charlton injected in 1945? should be an hyponym of the question’s focussubstance. The answer to In how many countries does Greenpeace have offices?should contain a number followed by a repetition of the focus countries. Sometypes of questions such as When was the Bombay Symphony Orchestra estab-lished? do not require the identification of a focus because, in this case, we lookfor the time named entity that when stands for. All the words of the question,whether they are part of the focus or not, play a role in the process of findingthe answer, at least through the information retrieval score (Sect. 2.2). We stressthat our classification of questions, the interpretation of the question’s focus andwhether an extraction function requires a focus or not are all motivated by tech-nical considerations specific to Quantum. A more rigorous study of questionsbased on psycho-linguistic criteria has been made by Graesser [5].
Before Quantum can analyze a question, it must undergo several operations:
tokenization, part-of-speech tagging and NP-chunking. The analysis itself is per-formed via a set of 60 patterns and rules based on words, part-of-speech tags andnoun-phrase tags. For example, Quantum uses the following pattern and rule toanalyze the question in Fig. 2:
how many <noun-phrase NP1> → type = cardinality, focus = NP1
The answer extraction mechanisms are too complex to be performed on the en-tire document collection. For this reason, we employ a classical search engine toretrieve only the most relevant passages before we proceed with answer extrac-tion. We use Okapi [6] because it allows for the retrieval of paragraphs instead ofcomplete documents. We query it with the whole question and we let it stem thewords and discard the stopwords. As a result, the query of the sample questionin Fig. 2 would be a best match of people, U.S., health and insurance. We keepthe 20 most relevant paragraphs along with their retrieval score as computed byOkapi.
The extraction function selected during question analysis (optionally parameter-ized with the focus) is applied on the most relevant paragraphs. Three techniquesor tools are used, depending on the extraction function: regular expressions,WordNet (for hypernyms/hyponyms relations) and the Annie named entity ex-tractor from the GATE suite [7]. For example, we would use WordNet to verifythat 37 million Americans can be an answer to the sample question in Fig. 2because Americans is an hyponym of the question’s focus people.
Each noun phrase in the relevant paragraphs is assigned an extraction score
when it satisfies the extraction function criteria. This extraction score is com-bined with the retrieval score of the source paragraph to take into account thedensity of the question keywords surrounding the extracted noun phrase. Thethree best-scoring noun phrases are retained as answer candidates. We decidedto consider noun phrases as base units for answers because we found that only2% of the questions from the past TREC campaigns could not be answered witha single noun phrase.
For Quantum as well as many other QA systems, the answer extraction phase isthe most complex. Therefore, it was the impact on this phase which was decisivein selecting among strategies to transform our monolingual system into a cross-language bilingual system. Two factors were predominant: the availability oflinguistic resources for answer extraction and the amount of work needed totransform the system.
Both factors argued in favour of an unmodified English answer extraction
module (Fig. 3a) and the addition of a translation module for the question andthe documents, instead of the creation of a new answer extraction module inFrench. On one hand, the quality and availability of linguistic resources is usuallybetter for English than French. In fact, many good quality English resources arefree, as it is the case for WordNet and the named entity extractor Annie used byQuantum. Furthermore, by retaining the answer extraction module in its original
language, fewer modifications are required to transform the monolingual system. Indeed, in order to write a new answer extraction module in the same languageas the questions (Fig. 3b), we would have to find linguistic resources for thatlanguage, adapt the system to the new resources’ interfaces and then translatewhole documents prior to extracting the answers, which is currently a time-consuming and error-prone process. On the other hand, it is more efficient totranslate only the question and the extracted answer. We will show that a fullsyntactically correct translation of the question is not mandatory and that thetranslation of the answer is facilitated by the particular context of QA.
Fig. 3. Two approaches for the transformation of an English (E) monolingual systeminto a cross-language system for French (F) questions. In (a), the system’s core remainsunmodified and better English linguistic resources can be used. In (b), the core istransposed to French, new resources in French need to be found and whole documentsneed to be translated.
In Fig. 3, we assume that the translation of the question and documents is
perfect so that it is completely external to the blackbox system. Unfortunately,machine translation has not yet reached such a level of reliability. It is currentlymore efficient to open the system in order to make the translation steps easier. Inour case, this allows us to avoid having to produce a complete and syntacticallycorrect translation of the question. It also allows us to use different translationmodels depending on the task.
We first replaced the question analysis module by a new French version
(Fig. 4) because the statistical techniques we use to translate the question are notreliable enough to produce syntactically correct sentences. Hence, our analysispatterns would seldom apply. Once the question is analyzed directly in French,the selected extraction function can be passed to the answer extraction modulealong with the question’s focus, if any. However, the focus must be translatedinto English because we have retained the original English answer extractionmodule (among other things, the focus has to be known by WordNet). As for thepassage retrieval module, we still use Okapi on the English document collection,which therefore requires translating the question keywords from French to En-
glish. Finally, the answer extraction module does not require any modification. Let us now examine each of the modified modules in more detail.
Fig. 4. Architecture of the bilingual version of Quantum (to be compared with themonolingual version in Fig. 2). The question and the answer are in French (F), whilethe documents are in English (E). The question analysis module operates in Frenchand the other modules remain in English. Translation is required at three points: forthe keywords, the focus and the answer.
Converting the Question Analysis Module and Translating theQuestion’s Focus
We use regular expressions that combine words and part-of-speech tags to ana-lyze a question. The original English module uses around 60 analysis patterns. We wrote about the same number of patterns for French.
We found that French questions were more difficult to analyze because of the
greater flexibility in the formulation of questions. For example, How much doesone ton of cement cost can be formulated in two ways in French: Combien coˆ
une tonne de ciment or Combien une tonne de ciment coˆ
English question words — the base of the analysis — do not always map to asingle equivalent in French: this is the case of what, which can be mapped toqu’est-ce que in What is leukemia / Qu’est-ce que la leuc´emie, to que in Whatdoes ”kain ayinhore” mean / Que signifie “kain ayinhore”, to quoi in Italy is the
largest producer of what / L’Italie est le plus grand producteur de quoi and to quelin What party did Occhetto lead / Quel parti Occhetto dirigeait-il. Among otherdifficulties there are the masculine/feminine and singular/plural agreements, theaddition of an euphonic t in the interrogative form of certain verbs in the 3rdperson singular (in Combien une tonne coˆ
utent-elles), elisions (Qu’appelle-t-on) and two forms of the past tense
(Quand le mur de Berlin a-t-il ´et´e construit / Quand le mur de Berlin fut-ilconstruit, while the only appropriate form in English is When was the BerlinWall built).
At the same time that the analysis rules select an extraction function, they
also identify the question’s focus. The focus semantics sometimes has an impacton the expected answer type. For instance, in What is the longest river in Nor-way, the focus river indicates that the answer is the name of a location. We useWordNet to make such links. This means that the focus from the French questionhas to be translated into English before the expected answer type is definitelyknown. To do so, we use an IBM2 [8] statistical translation model trained on aset of documents composed of debates of the Canadian Parliament, news releasesfrom Europa - The European Union On-Line and a sample of TREC questions. The IBM2 model is the simplest of the IBM series that takes into account theword’s position in the source sentence. We need this feature because we wanta translation that is the most probable given a particular word of the sourcesentence and, to a lesser degree, given all the other words of the source sentence. We keep only the best translation that is a noun.
We conducted an experiment on a sample set of TREC questions to mea-
sure the variation of performance between the original English question analysismodule and the new French module [3]. Tested on a set of 789 questions fromTREC, the regular expressions (used in conjunction with the semantic networkof WordNet) of the English module select the correct extraction function for96% of the questions. These questions were manually translated into French1and we found that the new French module selects the correct extraction func-tion for 77% of them. This drop is due to two factors: the narrower coverageof the regular expressions and the incorrect translation of the focus (the focusis correctly translated half of the times). Most of these translation errors aredue to the absence of the word in the training corpus, because many questionscontain rare words, especially in definitions: What is thalassemia, amoxicillin,a shaman, etc. The translation of the focus is crucial to the question answer-ing process. For example, it is almost impossible to determine that 37 millionAmericans can properly answer the sample question in Fig. 4 if the focus peopleis wrongly translated into flower.
Translating the Keywords for Passage Retrieval
Cross-language information retrieval has been widely addressed outside the QAdomain. State-of-the-art retrieval engines combine the translation model with
1 A French/English set of almost 2000 TREC questions is freely available on our
website at http://www-rali.iro.umontreal.ca/LUB/qabilingue.en.html
the retrieval model [9]. However, since the search engine we use does not allowmodifications to its retrieval model, we chose a simpler approach: we use anIBM1 translation model to get the best translations given the question and thenwe proceed as usual with Okapi. The selected target words are unordered and weretain only the nouns and verbs. Every word of the source sentence contributesequally to the selection of the best translations because the IBM1 model doesnot take the position of words into account, as the IBM2 model does. Hence,our method is slightly different from translating question keywords one by one. Our experiments showed that the best results are obtained when the query hasas many non-stopwords as there are in the original question (5 on average forthe CLEF questions).
We tested the cross-language passage retrieval module on the same TREC
test set as for the question analysis module. We obtained an average precisionof 0.570 with the original English module and an average precision of 0.467 withthe cross-language module. Unlike in the question analysis module, a translationerror does not compromise the location of the answer, as long as the queryincludes other keywords.
Even though it was not required at CLEF to translate the extracted answer backinto the same language as the question, our pilot project included this step inorder to make the QA process transparent to a French speaker. However, dueto a lack of time, we were unable to complete the answer translation module. Nevertheless, we believe that the particular context of QA should make thingseasier than in typical machine translation. For one thing, a lot of answers arenamed entities that do not require a translation. On a random set of 200 ques-tions from TREC, 25% have an answer that is a person or location name whichis identical in both languages, or a number, a date, a company name or a titlethat does not require a translation. To translate other types of answers, it wouldbe worth exploring the use of the question to help disambiguation.
We submitted two runs at CLEF: one with 50-byte answers and one with exactanswers. The underlying QA process is the same in both, apart from additionalchecks performed on the 50-byte snippets to avoid submitting an answer a secondtime if it is already encompassed in a better ranking string. Statistics on the runssubmitted at CLEF are listed in Table 1 (please refer to the CLEF 2003 MultipleLanguage QA track overview for details on the evaluation methodology). Asexpected, the 50-byte run performed better than the exact run, but the gap iswider than we anticipated: we estimated that only 2% of TREC questions couldnot be answered suitably by a single noun phrase but it appears that this numberis higher for CLEF, given the number of inexact answers we obtained. As for thenumber of unsupported answers, they remain a lesser concern.
Table 1. Statistics on the runs produced by Quantum on the French-to-English QAtask at CLEF. MRR stands for Mean Reciprocal Rank. Strict evaluation considersonly the right answers while lenient evaluation also considers inexact (too long or tooshort) answers and answers that are unsupported by the source document. Inexactand unsupported answers are not the total of inexact and unsupported answers in thewhole run but the number of questions missed because the correct answer was inexactor unsupported.
We wanted to compare the cross-language version of Quantum with the mono-
lingual English version. We ran the monolingual version on the English CLEFquestions and we obtained a MRR of 0.223 (exact answers, lenient evaluation). At CLEF, the cross-language version of our system obtained a MRR of 0.161on the French questions. As mentioned above, the principal reasons for this 28%performance drop include the different French question analysis patterns, thefocus translation and the keyword translation.
We also measured a drop of 44% after a similar experiment conducted on
TREC data [3]. We believe that CLEF questions were easier to process becausethey included no definition questions, thus there were less focus words to trans-late. We have also tried to translate our TREC question set with Babelfish2and then use the original English system, but with this approach performancedropped even more (53%).
We have shown how it is possible to transform an English QA system into a cross-language system that can answer questions asked in a different language thanthe document collection. In theory, it is possible to translate only the system’sinput/output (with Babelfish, for example) and to make no modification to theEnglish system itself. In practice, as long as machine translation will not produceperfect translations, it is more efficient to decompose the task and to plug intranslation at different points in the system. For our QA system Quantum, weuse an IBM1 translation model to get English keywords from the French questionfor passage retrieval. We then use a new set of French question analysis patternsto analyze the question, because the English patterns would hardly match abadly structured question translated automatically. The question’s focus is theonly part that needs to be translated. We use an IBM2 translation model for that
purpose. Overall, on the CLEF questions, the performance of our cross-languagesystem is 28% lower than the monolingual system.
We hope the cross-language QA systems that entered the CLEF campaign
will give French, Dutch, German, Italian and Spanish speakers access to a greateramount of information sources. For French speakers in particular, we have mea-sured that it is better to use a cross-language system (even one in a developmentstage) than to limit oneself to a monolingual French QA system on French doc-uments and therefore to be confined to one tenth the amount of informationavailable to English speakers.
This project was financially supported by the Bell University Laboratories, theNatural Science and Engineering Council of Canada and the National ResearchCouncil of Canada. We would also like to thank Elliott Macklovitch and GuyLapalme from the RALI, and Joel Martin from the NRC, for their help in con-ducting this research.
1. Clarke, C.L.A., Cormack, G.V., Laszlo, M., Lynam, T.R., Terra, E.L.: The Impact
of Corpus Size on Question Answering Performance. In: Proceedings of the 25thAnnual International ACM SIGIR Conference on Research Information Retrieval(SIGIR 02), Tampere, Finland (2002)
2. Plamondon, L., Lapalme, G., Kosseim, L.: The QUANTUM Question Answering
System at TREC-11. In: Notebook Proceedings of the Eleventh Text RetrievalConference (TREC-11), Gaithersburg, Maryland (2002)
3. Plamondon, L., Foster, G.: Multilinguisme et question-r´eponse: adaptation d’un
syst`eme monolingue. In: Actes de la 10e conf´erence sur le traitement automatiquedes langues naturelles (TALN 2003). Volume 2., Batz-sur-Mer, France (2003)
4. Voorhees, E.M.: Overview of the TREC 2002 Question Answering Track. In: Note-
book Proceedings of the Eleventh Text Retrieval Conference (TREC-11), Gaithers-burg, Maryland (2002)
5. Graesser, A., Person, N., Huber, J.
In: Mechanisms that Generate Questions.
Lawrence Erlbaum Associates, Hillsdale, New Jersey (1992)
6. Robertson, S., Walker, S.: Okapi/Keenbow at TREC-8. In: Proceedings of the
Eighth Text Retrieval Conference (TREC-8), Gaithersburg, Maryland (1998)
7. Cunningham, H., Maynard, D., Bontcheva, K., Tablan, V.: GATE: A Framework
and Graphical Development Environment for Robust NLP Tools and Applications. In: Proceedings of the 40th Annual Meeting of the Association for ComputationalLinguistics (ACL 2002), Philadelphia, Pennsylvania (2002)
8. Brown, P.F., Pietra, S.A.D., Pietra, V.J.D., Mercer, R.L.: The mathematics of
statistical machine translation: Parameter estimation. Computational Linguistics19 (1993) 263–311
9. Kraaij, W., Nie, J.Y., Simard, M.: Embedding Web-based Statistical Translation
Models in CLIR. Computational Linguistics 29 (2003) To appear.
Study on the effect application of Digiderm+ in comparison with formalin 4% on Digital Dermatitis (Mortellaro disease) in dairy cows. GD Deventer: Dr. M. Holzhauer, Dr. C. J. Bartels, and Dr. T.J.G.M. Lam WUR Wageningen: Ir. M. van ’t Riet and Dr. Ir. K. Frankena Introduction Digital Dermatitis or Mortellaro disease (DD) is the most important infectious claw disorder in dairy cows in
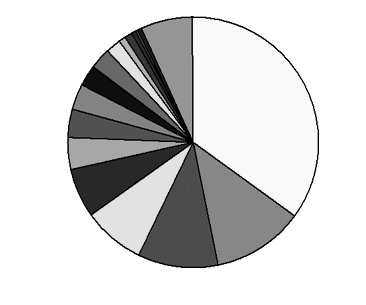 Fig. 1. Online language populations (March 2003), on a total of 640 million webpages.
Fig. 1. Online language populations (March 2003), on a total of 640 million webpages.